
大模型中间件是基于AI应用与大模型之间的中间层基础软件
2022年底,OpenAI基于大语言模型发布了聊天应用ChatGPT,推出仅一个月活跃用户破亿,吸引全球范围的广泛关注。ChatGPT的出现将人工智能推向全球关注的中心舞台,大语言模型带动的新一轮人工智能浪潮,正以前所未有的速度席卷全球。据统计,目前全球大型语言模型相关的创业公司已超过200家,投资总额达到70亿美元。
TechCrunch的数据显示,2022年前三个季度全球人工智能的投资已达到560亿美元,创下历史新高。其中,融资较高的创业公司包括Anthropic、Cohere、AI21 Labs等,这些公司的技术都建立在大型语言模型的基础之上。

大模型落地的挑战
对于个人用户,大语言模型带来了前所未有的高度个性化体验。它能够与用户进行流畅的对话,并提供即时且针对性的回应。借助基于大型语言模型的AI写作助手,用户能够快速生成高质量的文章草稿,其风格与用户贴合,极大提高了内容创作效率。然而,大模型要在企业侧真正落地仍然面临很大挑战,总结为下面四个方面:
大模型专业深度不够,数据更新不及时,缺乏与真实世界的连接。例如,在法律政策解读、电商客服、投资研报等专业领域中,由于大型模型缺乏足够的专业领域数据,用户在使用过程中经常会感觉大模型在一本正经地“胡说八道”。
大模型有Token的限制,记忆能力有限。大家之所以惊艳于ChatGPT流畅丝滑的对话能力,有很大一部分原因是其支持多轮对话。用户提问时,ChatGPT不但能理解意图,而且还能够基于之前的问答做综合推理。然而,大模型由于Token的限制,只能记忆部分的上下文。比如ChatGPT 3.5只能记忆4096个Token,无法实现长期记忆。
用户对于数据安全的担忧。大模型的出现让AI成为一种普惠技术,人人都可以基于大模型构建AI的应用。AI技术本身不再是商业壁垒,数据才是。而企业要想利用大模型构建商业,必须将自己的数据全部输送给大模型,以进行推理和表达。如何在数据安全可控的情况下使用大模型技术,成为一个亟待解决的问题。
使用大模型的成本问题。目前有两种模式可以使用大模型,一是将大模型本地化,用于再训练形成企业专有的模型。二是利用公有云模型,按照请求的Token数量付费。第一种方式成本极高,大模型由于有数千亿的模型参数,光部署计算资源的投资就得上亿。重新训练一次模型也需要近千万的投入,非常烧钱。这对于一般的中小企业是完全无法承受的。第二种方式企业构建的AI应用可以按照Token数量付费,虽然无需一次性的大额投入,但成本依然不低。以OpenAI为例,如果对通用模型进行微调(Fine-tuning)后,每使用1000个token(约600汉字)需要0.12美金。
企业级解决方案
针对上述问题,目前主要有三个解决方案:
第一是将大模型部署到企业本地,结合企业私有数据进行训练,打造垂直领域专有模型。
第二是在大模型基础上进行参数微调,改变部分参数,让其能够掌握深度的企业知识。
第三种是围绕向量数据库打造企业的知识库,基于大模型和企业知识库再配合Prompt打造企业专属AI应用。
从实用性和经济性的角度考虑,第三种是最为有效的解决方案。该方案大致实现方式如下所示。
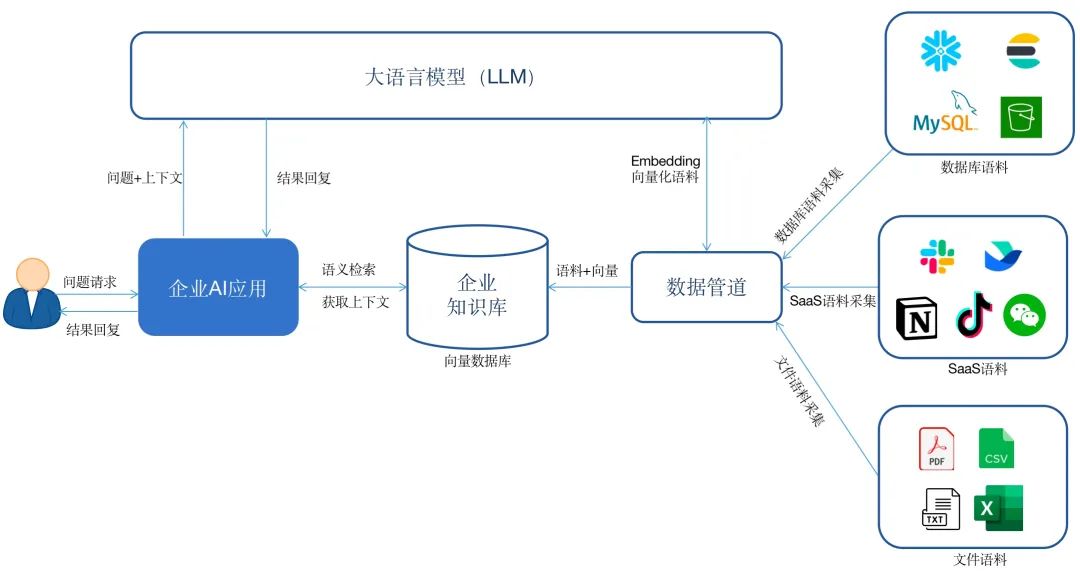
企业首先基于私有数据构建一个知识库。通过数据管道将来自数据库、SaaS软件或者云服务中的数据实时同步到向量数据库中,形成自己的知识库。
在这个过程中需要调用大模型的Embedding接口,将语料进行向量化,然后存储到向量数据库。当用户与企业AI应用对话时,AI应用首先会将用户的问题在企业知识库中做语义检索,然后将检索的相关答案和问题以及配合一定的prompt一并发给大模型,获得最终的答案之后回复给用户。
该方案有如下优势:
充分利用大模型和企业优势:既可以充分利用企业已有知识,又可以利用大模型强大的表达和推理能力,二者完美融合。
使AI应用具备长期记忆:Token的限制使大模型只能有短暂的记忆,无法将企业所有知识全部记住。利用外置的知识库,可以将企业拥有的海量数据资产全部整合,帮助企业AI应用构建长期记忆。
企业数据相对安全可控:企业可以在本地构建自己的知识库,避免核心数据资产外泄。
落地成本低:通过该方案落地AI应用,企业不需要投入大量资源建设自己的本地大模型,帮助企业节省动辄千万的训练费用。
大模型中间件
企业要落地该知识库方案仍然有一些具体问题需要解决,总结下来主要涉及三个方面。
第一方面是知识库的构建。企业需要将存在现有系统中的语料汇总到向量数据库,形成企业自有的知识空间,这个过程涉及数据采集、清洗、转换和Embedding等工作。语料来源比较多样,可能是一些PDF、CSV等文档,也可能需要接入企业现有业务系统涉及比如Mongodb、ElasticSearch等数据库,或者来自抖音、Shopify、Twitter等第三方应用。在完成数据的获取后,通常需要对数据进行过滤或者转化。这个过程中,从数据源实时地获取数据非常重要,比如电商机器人需要实时了解用户下单的情况,政策解读机器人需要了解最新政策信息。另外,对于数据Embedding的过程中涉及到数据的切块,数据切块的大小会直接影响到后面语义搜索的效果,这个工作也需要非常专业的NLP工程师才能做好。
其次是AI应用的集成。AI应用需要服务的用户可能存在于微信、飞书、Slack或者企业自有的业务系统。如何将AI应用与第三方SaaS软件进行无缝集成,直接决定用户的体验和效果。

评论